2 Gaza Strip Sample Design
The design adopted has been a stratified, 4-5 stages procedure involving
simple random sampling at each stage. Information about the survey population
was initially quite scarce. It seemed that the reliable, basic statistics
necessary for proper sampling would have to be produced during the process
of sampling itself. Fortunately, by the conclusion of the planning process
some of the information most needed for sample allocation, emerged in the
form of unpublished material provided by the Gaza statistical office. Thus
population figures which otherwise had to be estimated by enumeration of
some 100 neighbourhoods, became accessible.
Relevant sampling frames (directory, register of the household population)
for selection of households were not available. The final stages of the
sampling procedure therefore were carried out through "on-the-spot
sampling", involving map preparations prior to the data collection
stage.
Sampling Details
The complete sample design comprises the following steps:
1 Definition/construction of Primary Sampling Units (PSUs). The PSUs are
areas or localities which are easily identified on maps. In most cases a
PSU coincides with the administrative concept of a "locality",
for which more detailed maps were available.
2 The PSUs were stratified by type of locality (see table A.4). Strata are
labeled s (= 1,...,8), and PSUs are labeled k (= 1,2,...). The total number
of PSUs in stratum s is denoted K(s). We will use the notation "PSU
(s,k)" to denote the k'th PSU of the s'th stratum.
3 A 1st stage sample of PSUs to be surveyed were selected by simple random
sampling within each stratum. The sample number of PSUs in stratum s is
denoted k(s). The 1st stage sampling fraction for the s'th stratum is
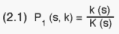
which in this case (simple random sampling) is the inclusion probability
of PSU (s,k) as well. (2.1) implies that all PSUs of the same stratum have
an equal chance of being included in the sample.
It may be seen from table A.4 that stratum 8, "Outside localities",
was not included in the sample. The character of these areas is somewhat
different from that of other localities, as there is no municipal authority.
On strict scientific grounds it could be argued that this particular feature
might require separate investigation in the present survey. However, the
estimated size of the population in these areas amounts to just 1% of the
Gaza Strip total, i.e. approximately 10 sample observations. Furthermore,
inclusion of the areas in the sample would require special measures as to
the sample design, and field work costs would be significantly higher than
elsewhere. Thus, exclusion of these few observations from the sample would
have negligible impact on aggregate survey results, while making practical
sense.
Table A.4 Stratification of primary sampling units (PSUs), 1st stage sample. Gaza Strip
| Stratum | Number of PSUs |
| No. | Type of locality | Population | Sample |
| s | | K (s) | k (s) |
| 1 | Gaza City EAST | 3 | 2 |
| 2 | Gaza City WEST | 3 | 1 |
| 3 | Towns | 4 | 2 |
| 4 | Northern Camps | 2 | 1 |
| 5 | Middle Camps | 4 | 1 |
| 6 | Southern Camps | 2 | 1 |
| 7 | Villages | 9 | 3 |
| 8 | Outside localities | 1 | 0 |
| TOTAL | 28 | 11 |
4 Each of the (sample) PSUs were subdivided into cells by using maps provided
by the local statistical office. For the 2nd stage selection of cells within
each of the sample PSUs, simple random sampling was applied.
Denote by B(s,k) the total number of population cells within PSU (s,k),
and by b(s,k) the number of cells included in the sample. Thus, the 2nd
stage sampling fraction (conditional inclusion probability) for the cells
(labeled c) of PSU (s,k) is:
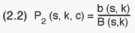
The B(s,k)s were counted by inspection of the maps of the sample PSUs. The
inclusion probability is independent of c, i.e. all cells of the same PSU
have an equal probability of being selected. The numbers of population and
sample cells for each of the PSUs selected at the 1st stage, are shown in
table A.5.
5 Due to the absence of satisfactory sampling frames for the cells, households
to be visited for the purpose of interview(s) had to be selected in the
field. We denote the total number of households of the cell D(s,k,c), and
the number to be included in the sample d(s,k,c). Rough estimates of the
(sample) D(s,k,c)s were provided by the Gaza statistical office.
However, prior to the selection of households an additional sampling stage
had to be imputed by the sampling of housing units. A "housing unit"
is a set of one or more households sharing a common main entrance (front
door) of a building or compound. In cases where there were several main
entrances, presumably leading to different groups of households, each would
be regarded as a separate housing unit.
During the process of sample preparations a procedure for direct selection
of sample households was considered. However, inspection of some cells showed
that such a procedure would generally be very difficult to implement, due
to complex housing structures, inadequate detailing and updating of maps,
non-display of road names and house numbers, absence of doorbells or other
hints to help identify pre-selected households. As opposed to the problems
of enumerating households, housing units (front doors) proved to be more
easily identifiable even in complex areas.
For each sample cell an enumeration system was developed for identifying
and selecting housing units. Briefly stated, it included random selection
of spots defining the starting points from which uniquely specified "enumeration
walks" (instructions for the directions of the walk and how to count
housing units) were to be initiated. During these walks every 3rd housing
unit was to be selected until a full subsample was obtained. For each "enumeration
walk" 4-6 housing units were normally selected. To help the data collectors
identify sample housing units, the field work supervisors were thoroughly
instructed - theoretically as well as through training in the field - in
the selection of housing units and preparation of map sketches of every
"enumeration walk".
In order to ease the practical identification, the starting points normally
were designated at corners of road crossings within the cells.
Denote by H(s,k,c) the total number of housing units within cell (s,k,c)
- a number which was not available prior to the field work. As mentioned
previously, estimates of the total number of households within the sample
cells, D(s,k,c), were available, providing an opportunity to estimate H(s,k,c)
upon completion of the field work.
The number of households included in housing unit (s,k,c,h) is denoted D(s,k,c,h).
The average number of households per housing unit of cell (s,k,c) can be
estimated from the sample data:
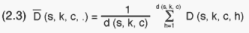
An estimate for the total number of cell housing units is thus:
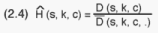
Multi-household housing units frequently, though not always, comprise households
which are closely linked through family ties, and are thus likely to be
more homogeneous than are households from different housing units. Therefore,
selecting more than one household from the same housing unit can be seen
as a waste of resources as observations may be highly correlated. The selection
of one household per sample housing unit implies more housing units - mutually
less homogeneous - to be included in the sample, which may cause smaller
sampling error.
When selecting just one household from each unit, the number of housing
units to be selected of course equals the number of households - i.e. d(s,k,c).
Thus, the sampling fractions for the two stages involved are:
Housing units (3rd stage):
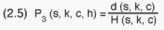
Households (4th stage):
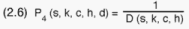
A special form carrying random numbers was prepared for the selection of
one household from a housing unit. The form used comprised separate columns
for every relevant total number of households within a housing unit (column
headings). Each column thus contained a sequence of random numbers less
than or equal to the total in the heading. Each random number was to be
used only once, and the questionnaire number entered into the form adjacent
to the number used in each particular case for control reasons.
Before selecting a household, all households of the housing unit were enumerated.
Standard rules for enumeration were:
- Enumeration should start from the top floor or top level and proceed downwards.
- Households on the same floor/level should be enumerated in clockwise order,
starting at the spot of entrance.
6 The respondent to the main questionnaire was to be the Head of Household.
In case the Head of Household was not available for interview, he/she might
be substituted by another household member likely to provide the same questionnaire
information as the Head of Household.
7 Sample of Individuals and Females
The gender of the RSI was decided prior to the field work. By doing this,
one could allocate more efficiently female enumerators to interview women,
which was considered paramount in order to ensure trust and confidentiality.
For the same reason, enumerators worked in pairs of the same sex.
The sample of individuals ("Randomly Selected Individual's (RSI) questionnaire")
as well as the sample of women ("Women's questionnaire") to be
interviewed were both derived from the sample of households.
The following procedure was adopted, based on the premise that the proportion
of women among the Gaza population of age 15 years or older is close to
50%.
- After the household (main) sample had been selected, a subsample of size
50% was drawn from the main sample. The subsample was selected separately
for each of the cells by simple random sampling. (If the number of cell
interviews was uneven, the "majority sex" of each cell was altered
successively so that the accumulated sex proportions for all cells approximated
the correct ones). Thus there were two subsamples - one female and one male.
The data collectors had particular instructions for deciding who was to
interview the various types of respondents.
- The members (15+) of each sex were to be enumerated for each sample household,
and the numbers, denoted W(s,k,c,h,d) for females and M(s,k,c,h,d) for males.
- The members (15+) of the pre-decided sex were then listed by descending
age.
- One of the individuals thus listed was selected by simple random sampling,
applying a random numbers form especially prepared for the random selection
of individuals (similar to the household selection form). The 5th stage
sampling fractions (selection probability for individual (s,k,c,h,d,i))
are thus:
Sample Allocation
In this section the calculations needed for allocating the Gaza household
sample among the various sample units are described. The aggregate overall
inclusion probability for an arbitrary household (s,k,c,h,d) is obtained
by multiplying the various selection probabilities at each of the first
four sampling stages:
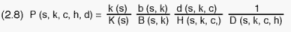
As can be seen on the right hand side of (2.8), this probability is independent
of the household index d, implying all households within the same housing
unit have equal inclusion probabilities. For the samples of males and females,
which are derived directly from the household sample, the probabilities
of inclusion are obtained by multiplying the household probabilities by
the 5th stage sampling fractions.
In (2.8) the statistics K(s), k(s) and B(s,k) are known. The statistic D(s,k,c,h)
is observed from the sample, and H(s,k,c) is estimated from sample data
by (2.4). Thus it remains to determine the b(s,k)s and the d(s,k,c)s.
Allocation of Sample of Cells - b(s,k)
The number of cells to be selected from the various sample PSUs, the b(s,k)'s,
are determined as follows: The 1st stage sampling fractions, P1 (s, k),
are already fixed (Table A.4). The 2nd stage fractions,
P2 (s, k, c), are determined so that:
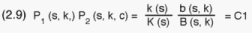
C1 is a constant for all PSU (s,k)s. Formula (2.9) implies the design for
sampling of cells be an epsem one (equal probability selection method for
all strata and PSUs).
On the average per sample cell 10 households were to be selected. Having
a total Gaza sample size of 960 households, the number of cells to be selected
at the 2nd stage was thus 96, i.e. the sum of the b(s,k)s over all sample
PSUs amounts to 96. (Due to numerical approximations the actual calculations
implied 97 cells to be selected and the total household sample size to be
964).
The expression (2.9) can be rearranged:
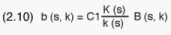
Except for the constant C1, all the statistics on the right hand side of
(2.10) are known. C1 is determined by taking the sum of all (sample) (s,k)
of both sides of (2.10):
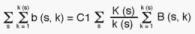
On the left hand side the sum is 96, while the sum on the right hand side
amounts to C1 multiplied by some (known) factor. Hence, C1 is fixed, and
the number of sample cells within each of the sample PSUs, the b(s,k)s,
is determined from (2.10) by insertion of the respective numbers.
Allocation of Sample of Housing units and Households -d(s,k,c)
As the cell total number of housing units, H(s,k,c), was unknown at the
stage of sample allocation, the housing unit sample size for each of the
cells had to be determined indirectly by using the information on the cell
total number of households, D(s,k,c). Thus a distinction has to be made
between the allocation task and the calculation of inclusion probabilities.
In order to determine the number of housing units to be selected from each
sample cell, d(s,k,c), we would require the sample size to be proportionate
to the total number of households, D(s,k,c), i.e.
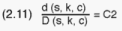
Here, C2 would be constant. By rearranging (2.11) we would get:
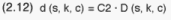
Taking the sum of all sample cells (s,k,c) of both sides of (2.12), the
left hand side adds up to 960, while the right hand side adds up to some
known multiple of C2:
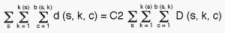
Thus, C2 is determined, and the cell sample size of households is finally
calculated by formula (2.12). This way of allocating is what would have
been done if households could be selected directly without the intermediate
stage of housing unit selection. In this case the household sample would
have been an epsem one. However, the introduction of the housing unit stage
makes application of an epsem design for household selection practically
impossible.
Table A.5 shows the number of population and sample cells for each of the
sample PSUs. The aggregate PSU household sample size, i.e. the sum of sample
households over all sample cells within each sample PSU, is also displayed.
Table A.5 Population and sample number of cells, and aggregate household sample size (d(s,k)) for each of the sample PSUs. Gaza Strip
| | | Number of cells | |
| No. | Name of sample PSU | Population | Sample | PSU household sample size |
| s | (s,k) | B (s,k) | b (s,k) | d (s,k) |
| 1 | Zaitoun N | 105 | 25 | 4 | 29 |
| Shajaeya N | 106 | 49 | 9 | 114 |
| 2 | Rimal N | 104 | 20 | 7 | 44 |
| 3 | West Khan Yunis S | 109 | 17 | 4 | 52 |
| Rafah Town S | 110 | 31 | 7 | 97 |
| 4 | Shati Camp N | 103 | 73 | 17 | 120 |
| 5 | Bureij Camp S | 107 | 25 | 12 | 122 |
| 6 | Rafah Camp S | 111 | 68 | 16 | 154 |
| 7 | Jabalia Village N | 102 | 40 | 14 | 157 |
| Beit Lahia N | 101 | 11 | 4 | 40 |
| Qararah S | 108 | 8 | 3 | 35 |
| TOTAL | 367 | 97 | 964 |
|

